 Objetivos:
Objetivos:
• Tener un concepto claro sobre las pseudo-columnas de
Oracle.
• Conocer los tipos de Pseudocolumnas en
Oracle.
• Ver las Ventajas que Ofrecen.
NOTA: Usamos como ejemplo la Base de Datos: ORCL, la cual viene por defecto en cualquier versión de ORACLE.
____________________________________________________________________________________
Pseudocolumns
Las Pseudocolumnas se comportan como columnas reales en una tabla, aunque realmente no lo son. Pueden ser consideradas como elementos de datos de propósito especial que se pueden utilizar en sentencias
SQL como si fueran parte de la tabla, pero no están contenidas en una tabla. Esencialmente, una pseudo-columna es un valor asignado de
Oracle usado en el mismo contexto que una columna de
Oracle, pero sin estar almacenada en el disco
.[1]
Una pseudocolumna también es similar a una función sin argumentos. Sin embargo, las funciones sin argumentos típicamente devuelven el mismo valor para cada fila del conjunto de resultados, mientras que las pseudocolumnas normalmente devuelven un valor diferente para cada fila
.[2]
Debe tener presente que si bien es posible seleccionar valores de una pseudocolumna, no es posible realizar operaciones
DML tales como:
INSERT INTO,
UPDATE o
DELETE sobre ellas.
En
Oracle existen un considerable número de Pseudocolumnas las cuales podrían clasificarse de acuerdo al contexto, a continuación presentamos un lista parcial de ellas:
Pseudocolumnas de Secuencias
Como ya sabemos, una secuencia es un objeto de esquema que puede generar valores secuenciales únicos. Estos valores se utilizan a menudo para claves primarias y únicas. Puede consultar valores de secuencia en sentencias SQL (En cualquier versión Oracle) y PL/SQL (11g en adelante) con estas pseudocolumnas:
NEXTVAL: Incrementa la secuencia y devuelve el siguiente valor.
CURRVAL: Devuelve el valor actual de una secuencia.
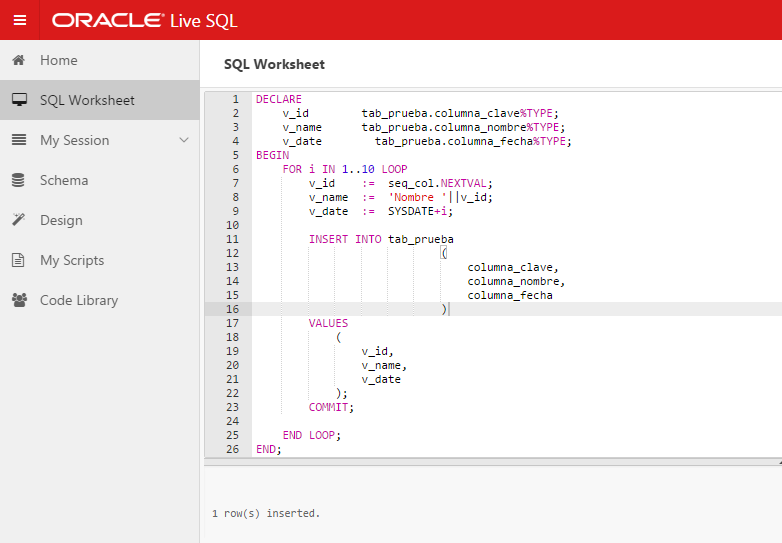
Ejemplos:
CREATE SEQUENCE sec_prueba
START WITH 1
INCREMENT BY 1
NOCYCLE;
/*Creamos la secuencia sec_prueba para a continuación usar las pseudocolumnas NEXTVAL y CURRVAL.*/
---
SELECT sec_prueba.NEXTVAL
FROM dual;
/*Realizamos una simple consulta en la cual usamos la pseudocolumna NEXTVAL; Este ejemplo aplica a cualquier versión Oracle.*/
---OUTPUT:
SELECT sec_prueba.CURRVAL
FROM dual;
/*Realizamos una simple consulta en la cual usamos la pseudocolumna CURRVAL; Este ejemplo aplica a cualquier versión Oracle.*/
---OUTPUT:
SET SERVEROUTPUT ON
DECLARE
v_seq NUMBER;
v_date DATE;
BEGIN
v_seq := sec_prueba.NEXTVAL;
DBMS_OUTPUT.PUT_LINE('El valor generado es: '||v_seq);
DBMS_OUTPUT.PUT_LINE('Valor actual: '||sec_prueba.CURRVAL);
END;
/*Este ejemplo muestra que es posible usar las pseudocolumnas NEXTVAL y CURRVAL en un bloque de PL/SQL(de 11g en adelante).*/
---OUTPUT:
Pseudocolumnas de Consulta de Versión/Version Query Pseudocolumns
Las pseudocolumnas de consulta de versión son válidas sólo en
consultas de flashback de Oracle. A continuación una lista de ellas:
• VERSIONS_STARTTIME: Devuelve el TIMESTAMP de la primera versión de las filas devueltas por la consulta.
• VERSIONS_STARTSCN: Devuelve el SCN de la primera versión de las filas devueltas por la consulta.
• VERSIONS_ENDTIME: Devuelve el TIMESTAMP de la última versión de las filas devueltas por la consulta.
• VERSIONS_ENDSCN: Devuelve el SCN de la última versión de las filas devueltas por la consulta.
• VERSIONS_XID: para cada versión de cada fila, devuelve el ID (un número RAW) de la transacción que creó esa versión de fila.
• VERSIONS_OPERATION: Para cada versión de cada fila, devuelve un carácter que representa la operación que causó esa versión de fila. Los valores devueltos son I (para una operación de inserción), U (para una operación de actualización) o D (para una operación de borrado).
Ejemplos:
INSERT INTO hr.employees
(
employee_id,
last_name,
email,
hire_date,
job_id
)
VALUES
(
1111,
'Aponte',
'aponte@',
SYSDATE,
'IT_PROG'
);
COMMIT;
/*Insertamos un nuevo registro en la tabla employees.*/
---
SELECT
VERSIONS_STARTTIME,
VERSIONS_STARTSCN,
VERSIONS_ENDTIME,
VERSIONS_ENDSCN,
VERSIONS_XID,
VERSIONS_OPERATION,
employee_id,
last_name,
email
FROM hr.employees
VERSIONS BETWEEN SCN MINVALUE AND MAXVALUE
WHERE employee_id = 1111;
/*Consultamos el nuevo registro insertado en la tabla employees; Notar que el registro con el VERSIONS_STARTSCN = 5973562155948, en VERSIONS_OPERATION tiene: I (INSERT) y que VERSIONS_ENDTIME y VERSIONS_ENDSCN contienen valores nulos, esto porque este registro representa la ultima versión(No había sufrido cambios hasta ese momento).*/
---OUTPUT:
UPDATE hr.employees
SET last_name = 'Castillo'
WHERE employee_id = 1111;
COMMIT;
/*En este ejemplo procedemos a modificar el registro anteriormente insertado en la tabla employees; al volver a ejecutar la consulta, notamos lo siguiente: El anterior registro con el VERSIONS_STARTSCN = 5973562155948 ahora tiene valores en los campos: VERSIONS_ENDTIME y VERSIONS_ENDSCN; El nuevo registro con el VERSIONS_STARTSCN = 5973562155974 contiene: U (UPDATE) en VERSIONS_OPERATION y su VERSIONS_ENDTIME y VERSIONS_ENDSCN están nulos.*/
---OUTPUT:
Para más información acerca de las consultas
flashback de Oracle hacer
click aquí.
Pseudocolumna ROWID
Para cada fila de la Base de Datos, la pseudocolumna ROWID devuelve la dirección de la fila. Los valores ROWID de Oracle contienen la información necesaria para localizar una fila.
Normalmente, un valor ROWID identifica de forma única una fila en la Base de Datos. Sin embargo, las filas en tablas diferentes que se almacenan juntas en el mismo clúster pueden tener el mismo ROWID.
Los valores de la pseudocolumna ROWID tienen el tipo de datos ROWID o UROWID.
Entre los usos mas importantes de los ROWID podemos mencionar:
• Son la forma más rápida de acceder a una sola fila.
• Pueden mostrarle cómo se almacenan las filas de una tabla.
• Son identificadores únicos para filas en una tabla.
• No debe utilizar ROWID como clave principal de una tabla. Por ejemplo, si elimina y vuelve a insertar una fila con las utilidades de importación y exportación (Import and Export utilities), puede que su ROWID cambie. Si elimina una fila, Oracle puede reasignar su ROWID a una nueva fila insertada posteriormente.
Nota: si usas
Toad for Oracle y ejecutas una consulta ordenando por el
ROWID, puedes editar los valores en los campos de la tabla de forma manual en el Data Grid (ejemplo mas adelante).
Ejemplos:
DECLARE
v_max_emp NUMBER;
CURSOR c_max_emp IS
SELECT MAX(employee_id)
FROM hr.employees;
BEGIN
OPEN c_max_emp;
FETCH c_max_emp INTO v_max_emp;
CLOSE c_max_emp;
FOR i IN 1..5 LOOP
v_max_emp := v_max_emp+i;
INSERT INTO hr.employees
(
employee_id,
last_name,
email,
hire_date,
job_id
)
VALUES
(
v_max_emp,
'Emp '||i,
'correo'||i||'@',
SYSDATE,
'IT_PROG'
);
END LOOP;
COMMIT;
END;
/*Con este Bloque de PL/SQL procedemos a insertar 5 registros mas en la tabla employees.*/
---
SELECT
ROWID,
employee_id,
last_name,
email
FROM hr.employees
WHERE employee_id > 1111;
/*Consultamos los empleados insertados en el ejemplo anterior para así notar cada ROWID.*/
---OUTPUT:
SELECT *
FROM hr.employees
WHERE employee_id = 1111
ORDER BY ROWID;
/*Consultamos el registro insertado en ejemplos anteriores y ordenamos la consulta por el ROWID para así poder editar los datos directamente desde el Data Grid (solo en Toad for Oracle)*/
---OUTPUT:
Pseudocolumna ROWNUM
Para cada fila devuelta por una consulta, la pseudocolumna ROWNUM devuelve un número que indica el orden en que Oracle selecciona la fila de una tabla o conjunto de filas unidas. La primera fila seleccionada tiene un ROWNUM de 1, el segundo tiene 2, y así sucesivamente.
Ejemplos:
SELECT
ROWNUM,
employee_id,
last_name,
email
FROM hr.employees
WHERE employee_id > 1110;
/*Consultamos los registros que hemos insertado recientemente; Notar como se muestra el ROWNUM de cada linea.*/
---OUTPUT:
SELECT
ROWNUM,
employee_id,
last_name,
email
FROM hr.employees
WHERE employee_id > 1110
AND ROWNUM < 4;
/*Este ejemplo muestra que es posible usar la pseudocolumna ROWNUM en la cláusula WHERE de una consulta.*/
---OUTPUT:
Pseudocolumnas de consultas jerárquicas
Para más información acerca de las consultas
Consultas Jerárquicas de Oracle hacer
click aquí.
Pseudocolumna LEVEL
Para cada fila devuelta por una consulta jerárquica, la pseudocolumna LEVEL devuelve 1 para una fila raíz, 2 para un hijo de una raíz, y así sucesivamente. Una fila raíz es la fila más alta dentro de un árbol invertido. Una fila secundaria es cualquier fila no raíz. Una fila principal es cualquier fila que tiene hijos. Una hilera de hojas es cualquier hilera sin hijos.
Tenga en cuenta que es posible usar la pseudocolumna LEVEL en consultas normales, no solo en consultas jerárquicas. A continuación un ejemplo:
SELECT
LEVEL,
CASE
WHEN LEVEL > 4 THEN 'ALTO'
WHEN LEVEL < 3 THEN 'BAJO'
ELSE 'MEDIO'
END AS consideración
FROM dual
CONNECT BY LEVEL <= 5
ORDER BY LEVEL DESC;
____________________________________________________________________________________
Para una lista Detallada de las pseudocolumna s de Oracle seguir el siguiente Link:
Fuentes: https://docs.oracle.com/cd/B19306_01/server.102/b14200/pseudocolumns.htm
































{kind=link}